

Sélection des vues à matérialiser

Le problème de la sélection des vues
L’administrateur d’un entrepôt doit déterminer quelles vues doivent être matérialisées. Il dispose d’un espace de stockage limité et de capacités de calcul finies. Il doit aussi garder l’entrepôt à jour. En somme, il ne peut pas tout matérialiser.
Il y a des millions, des milliards de vues possibles !
Dans un entrepôt de données, il peut y avoir des millions ou des milliards de vues possibles à matérialiser, même si on se limite aux vues ayant une forme très précise.
Par exemple, prenons le cas d’une table ayant 20 colonnes. Il est facile de voir qu’il y a $2^{20}-1$ requêtes de la forme suivante :
select dimi,...dimj, count(*) from table group by dimi,...dimj;Prenons un cas particulier avec 4 colonnes nommées revenu, produit, pays, vendeur, il y a alors $2^4-1=15$ vues possibles de ce type. Pouvez-vous les énumérer ?
Et la taille des vues ?
L’administrateur d’un entrepôt doit tenir compte de la taille des vues. Idéalement, il veut matérialiser de petites vues parce qu’elles nécessitent peu d’espace de stockage et qu’il peut ainsi en matérialiser plusieurs.
Malheureusement, il est souvent impossible de connaître la taille des vues avant de les avoir calculées ! Voilà qui n’est pas très pratique ! Avant même de savoir si une certaine vue doit être matérialisée, il faudrait la matérialiser pour en connaître la taille ? Heureusement, nous allons voir dans le prochain article de cette semaine qu’on peut estimer la taille des vues sans avoir à faire trop de travail.
C’est un problème NP-difficile !
Le problème de sélection des vues est considéré comme un problème NP-difficile. On cite fréquemment Gupta [1] à ce sujet. Il invoque une réduction du problème de la couverture minimale vers un problème particulier de sélection des vues. (Ce problème de la couverture minimale, connu pour être NP-difficile, consiste à trouver le plus petit nombre d’ensembles capables de couvrir tous les éléments possibles. Voir l’article dans Wikipédia pour plus de détails.)
Personnellement, nous préférons invoquer un autre problème NP-difficile, le problème du sac à dos. Dans ce problème, nous avons un sac à dos capable de porter un poids maximal. Nous avons aussi différents objets ayant différentes valeurs et différents poids. Il faut choisir les objets qui maximisent la valeur totale sans pour autant dépasser le poids permis. Remplaçons le sac à dos par un espace de stockage, le poids des vues par leur taille (en bits) et leur valeur par une mesure de l’utilité de la vue pour accélérer les requêtes des utilisateurs. On voit alors que le problème du sac à dos devient une métaphore pour un type particulier de problème de sélection des vues.

Illustration du problème du sac à dos
En somme, cela signifie qu’il est impossible, en général, de demander à un ordinateur de sélectionner un ensemble de vues de manière optimale. Même en supposant que nous disposions de toutes les informations, incluant la taille de toutes les vues, il est très improbable qu’on puisse faire une sélection automatique optimale des vues dans un temps convenable au sein d’un entrepôt d’une taille et d’une complexité réalistes.
Algorithme glouton
Bien que le problème de sélection des vues soit difficile, il existe des solutions pratiques qui fonctionnent généralement bien. Par exemple, on utilise fréquemment des algorithmes gloutons pour résoudre approximativement le problème de la sélection des vues.
Dans un algorithme glouton, au lieu de chercher une solution qui est globalement optimale, on cherche toujours le meilleur prochain choix. Dans le cas du problème du sac à dos, on commence à mettre les objets dont le rapport prix/poids est le plus élevé. Il n’y a malheureusement aucune garantie qu’une telle approche soit optimale, mais l’expérience montre que cela fonctionne suffisamment bien [2].
La figure suivante illustre l’algorithme glouton utilisé pour résoudre le problème du sac à dos :
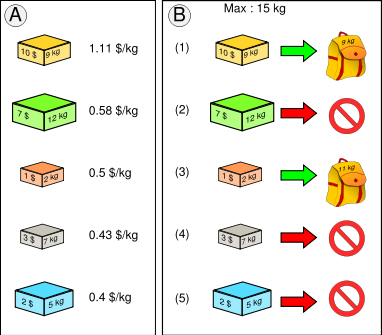
Illustration de l’algorithme glouton pour le problème du sac à dos
Malheureusement, dans le contexte de la sélection des vues, nous n’avons pas toujours une idée juste de l’utilité des différentes vues. En effet, comment prédire les requêtes les plus fréquentes avant même d’avoir conçu l’entrepôt de données ? Heureusement, au fil du temps, on peut accumuler des statistiques d’utilisation et connaître ainsi la valeur relative des différentes vues. Mais le problème n’est pas nécessairement stationnaire : certains vues très populaires au mois de septembre ne le sont peut-être plus au mois de décembre !
Un algorithme glouton particulièrement simple, qui peut s’utiliser sans rien connaître de la structure ou de l’utilisation de l’entrepôt de données, consiste à matérialiser d’abord les vues dont la taille est la plus petite. (Évidemment, encore faut-il connaître la taille des vues en question !)
Notez qu’il arrive que, dans des entrepôts, l’espace de stockage ne soit pas la limite la plus importante. Le coût de la mise à jour des vues peut être un problème plus important dans les entrepôts fréquemment mis à jour. Dans un tel cas, il faudra estimer le temps de mise à jour des vues plutôt que la taille des vues.
Et les index ?
Nous n’avons couvert jusqu’à maintenant que le problème de la sélection des vues. Cependant, nous traitons ici une vue comme une forme d’index, c’est-à-dire qu’il s’agit d’une structure auxiliaire dont la fonction principale est d’accélérer les requêtes.
Mais pratiquement tout ce que nous venons de décrire s’applique aussi au problème de la sélection des index ! Le problème de la sélection des index est également NP-difficile.
Alors pourquoi se préoccuper autant des vues ? Parce que la matérialisation des vues pour accélérer les requêtes est une stratégie particulièrement utile dans les entrepôts de données. En effet, ce type de requêtes dans les entrepôts se prête mieux à la matérialisation de nombreuses petites vues. Par exemple, on demande souvent à un entrepôt de fournir des données concernant l’ensemble de nos opérations. Ce type de requête est facile à accélérer avec la matérialisation des vues. Par ailleurs, les entrepôts de données sont souvent mis à jour moins fréquemment ce qui rend la mise à jour des vues abordable.
[1] Himanshu Gupta, Selection of Views to Materialize in a Data Warehouse, ICDT’97, 1997.
[2] À la suite d’une transaction, lorsque l’on donne la monnaie en commençant toujours par donner les pièces qui ont une plus grande valeur, on utilise un algorithme glouton.
